En esta segunda entrega sobre el uso de la
distribución de Poisson para
predecir resultados de partidos de Futbol vamos a exponer como podemos comprobar si nuestros datos se ajustan a este tipo de distribución o no. Esto se conoce en estadística como
test de bondad de ajuste o, en inglés,
goodness of fit test.
Este proceso que vamos a explicar se puede utilizar con cualquier tipo de variable en escala nominal u ordinal y sirve para cualquier tipo de distribución.
El test está basado en la
distribución chi cuadrado (
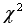
) y fue creado por uno de los más reputados estadísticos de los últimos tiempos,
Karl Pearson. Su base, como en todos los test de hipótesis, consiste en establecer dos hipótesis, la hipótesis nula que considera que los datos que tenemos se ajustan a una determinada distribución y la hipótesis alternativa que es la negación de la nula, es decir, nuestros datos no se ajustan a la distribución. Dicho así no parece muy claro, pero es como se suele explicar la teoría. Traducido al cristiano sería algo así: Tenemos unos datos que
'parece' que siguen una determinada distribución, pero hay unas
diferencias entre los datos que tenemos (
observados) y los que deberían de ser (
esperados). ¿Son esas diferencias lo suficientemente grandes para que sean provocadas por el azar?. La respuesta a esta pregunta la obtendremos con el test de bondad de ajuste.
Alguno a estas alturas se estará preguntando, ¿pero para que necesito hacer esto, si saco la media y lo meto en la fórmula de Poisson y obtengo el resultado que necesito?. La respuesta es sencilla, si nuestros datos no siguen la distribución de Poisson, todas las predicciones que hagamos utilizando las fórmulas para esta distribución serán erroneos y si nos basamos en ellos para apostar, tenemos muchas posibilidades de ver numeros rojos en nuestro bank a final de temporada.
Después de este pequeño paréntesis económico, vamos a ver como podemos
realizar el test de bondad de ajuste a una distribución de Poisson en Excel.
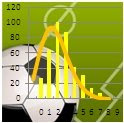
Para ello tomaremos los datos del
total de goles marcados por partido en la primera división durante la temporada 2007-2008. Pulsando sobre estadísticas tendremos el resumen de los datos que necesitamos. Estos serían nuestros valores
'Observados'. El siguiente paso que debemos hacer es calcular la media de los goles totales marcados por partido. Al tener los datos resumidos no podemos utilizar la función
promedio() si no que debemos hacer una especie de 'desagrupamiento'. Esto, como siempre, se puede hacer de varias formas, yo voy a explicar dos de ellas, las más sencillas.
La primera es crear una nueva columna en la que multiplicaremos el número de goles por la cantidad de partidos (Columna C). Sumaremos todos esos productos y dividiremos este valor por el total de partidos jugados.
La otra es usar la formula
sumaproducto(A2:A11;B2:B11) y nos ahorramos el paso de las multiplicaciones, que lo hace excel internamente. El resultado es el mismo para ambos casos, ¡Faltaria más!.
Una vez calculada la media, lo que hacemos es determinar los valores
'Esperados' según una distribución de Poisson con esa media. Esto lo calculamos multiplicando la probabilidad de Poisson para cada resultado, por el total de partidos.
La última columna la utilizaremos para calcular el estádistico
con la siguiente fórmula:
Esta columna es importante, porque nos da información de donde se producen las mayores discrepancias. Cuanto mayor sea el valor que obtengamos, mayor es la discrepancia entre el valor observado y el esperado. Más alejado está ese punto de su lugar teórico predicho por la curva de Poisson y más probabilidad tenemos de que el resultado del test nos diga que nuestros datos no se ajustan bien a la curva.
Ya solo nos queda sumar todos estos valores y 'buscar' dentro de la función
y comprobar si las diferencias que hemos encontrado son lo suficientemente grandes o no para rechazar o no rechazar la hipótesis nula. Ya veis que he dicho rechazar o no rechazar, en lugar de rechazar o aceptar, porque
NUNCA se acepta la hipótesis nula. Este es un error muy común en la interpretación de los resultados de test de este tipo. Pero dejaremos esto para un futuro.
La función
tiene dos parámetros, el primero de ellos es el valor de nuestra suma, y el segundo son los grados de libertad para los que vamos a calcular este estadístico.
Los grados de libertad se obtienen con la siguiente fórmula: GL = Nc - Np - 1
Siendo Nc = al número de categorías que tenemos y Np = número de parámetros que estamos estimando. Para nuestro caso tenemos 10 categorías y vamos a estimar un parámetro solo que es la media: GL = 10 - 1 - 1 = 8
El valor que nos devuelve es lo que en estadística se llama
P-Value, y corresponde a la probabilidad de equivocarnos si rechazamos la hipótesis nula. Como norma general se suele tomar como valores de corte el 5% ó el 1% dependiendo de lo restrictivos que seamos. Este valor
lo debemos de tomar ANTES de la realización del test y será nuestro límite para rechazar o no rechazar la hipótesis nula.
En el ejemplo tenemos un P-Value de 0.54 con lo que debemos decir que las diferencias que hemos encontrados no son lo suficientemente grandes como para decir que nuestros datos no siguen una distribución de Poisson. Como esto es un poco engorroso, hay mucha gente, que viendo este P-Value, adopta una postura más comprometida y llega a decir que nuestros datos siguen una distribución de Poisson. Pero como ya he explicado esto no es del todo cierto, puede que siga una distribución de Poisson o puede que se acerquen más a otro tipo de distribución. El aspecto final de la hoja sería el siguiente:

Como no quiero extenderme más, solo hago una puntualización final. Si os fijais tenemos dos categorías con menos de 5 datos (8 y 9 goles), siendo estrictos deberíamos haber agrupado estas dos categorías y crear una nueva como más de 6 goles, agrupando en ella las categorias 7, 8 y 9 goles. El resultado del test varía poco en este caso, así que para no complicar más la explicación lo he dejado así. Si alguno está interesado en como se haría el test en este caso que lo diga y lo explicaremos.
Un saludo y hasta la próxima
EDITO 22/07/10: Al final he encontrado una forma de añadir hojas de cálculo al blog y he creado una mini hoja Excel para calcular los resultados de un partido de Futbol a partir de la media de goles marcados por cada equipo. La hoja la teneís
aqui.

 Para los puntos visitantes no ocurre lo mismo. El desajuste más importante se ve al final de la temporada con unas diferencias superiores a los 2.5 puntos entre el valor real y el estimado. Los modelos predecían menos puntos que los que en realidad anotaban los equipos visitantes. Este es el error más grande que hemos encontrado hasta ahora.
Para los puntos visitantes no ocurre lo mismo. El desajuste más importante se ve al final de la temporada con unas diferencias superiores a los 2.5 puntos entre el valor real y el estimado. Los modelos predecían menos puntos que los que en realidad anotaban los equipos visitantes. Este es el error más grande que hemos encontrado hasta ahora. Para el Spread tenemos un gráfico muy similar al anterior. Las predicciones fueron bastante buenas durante toda la temporada pero debido a ese fallo en las predicciones para los puntos visitantes en el tramo final tenemos un desajuste de más de 1.5 puntos. Las casas colocaban lineas de spread 1.5 puntos de media más bajas de lo que en realidad eran.
Para el Spread tenemos un gráfico muy similar al anterior. Las predicciones fueron bastante buenas durante toda la temporada pero debido a ese fallo en las predicciones para los puntos visitantes en el tramo final tenemos un desajuste de más de 1.5 puntos. Las casas colocaban lineas de spread 1.5 puntos de media más bajas de lo que en realidad eran. En este último gráfico se aprecia lo mismo que en los dos anteriores. Buenas predicciones durante toda la temporada pero fallo en el tramo final de más de 3 puntos en media.
En este último gráfico se aprecia lo mismo que en los dos anteriores. Buenas predicciones durante toda la temporada pero fallo en el tramo final de más de 3 puntos en media.














































